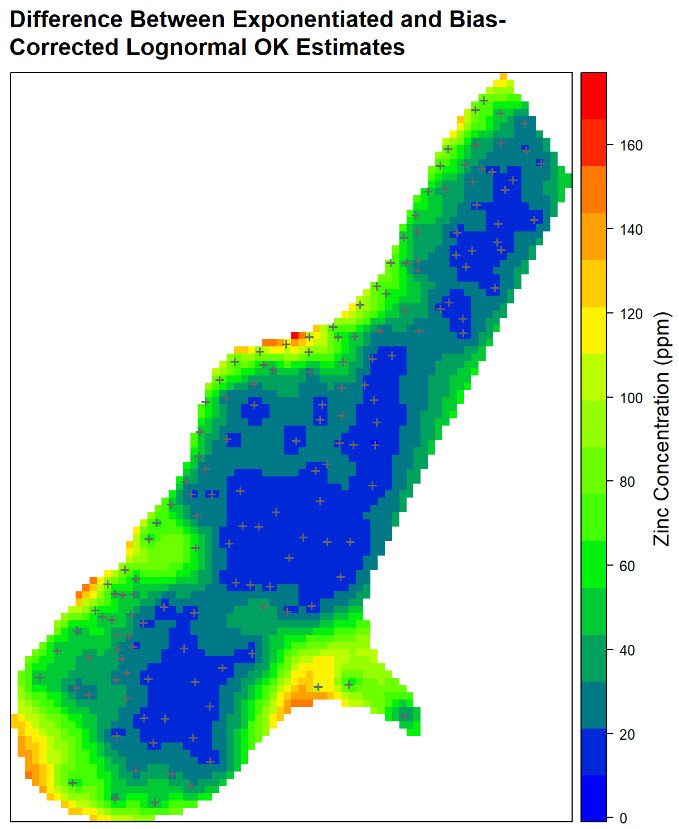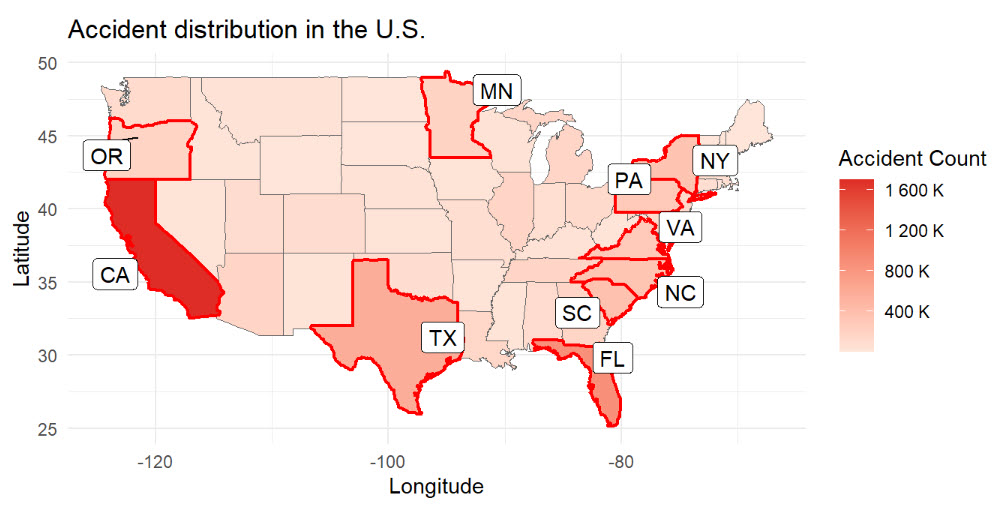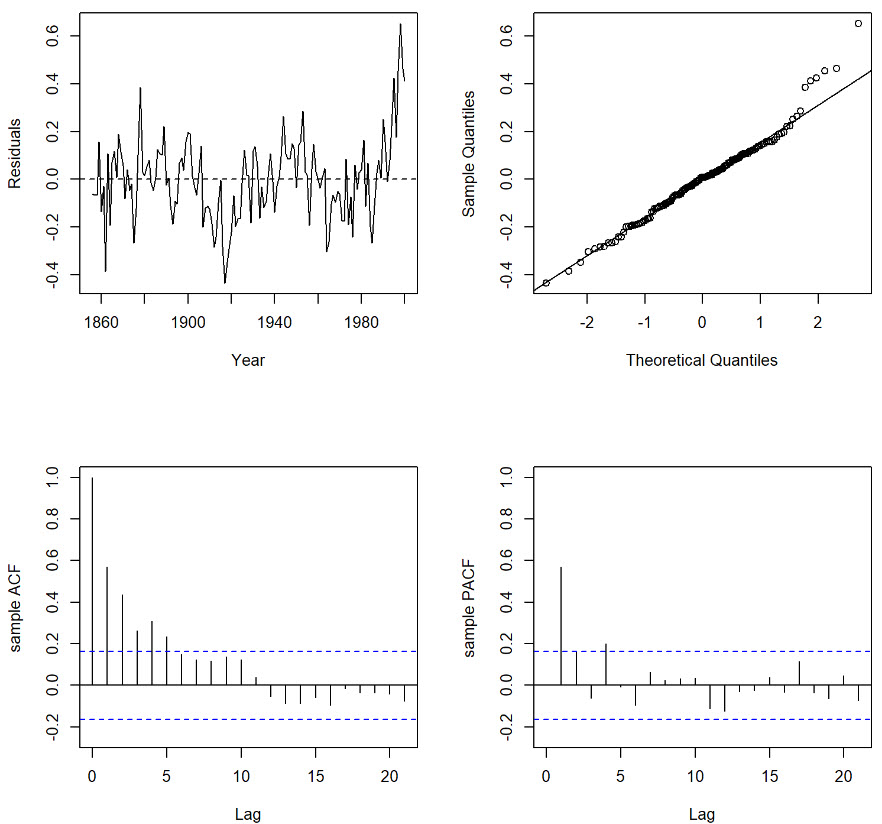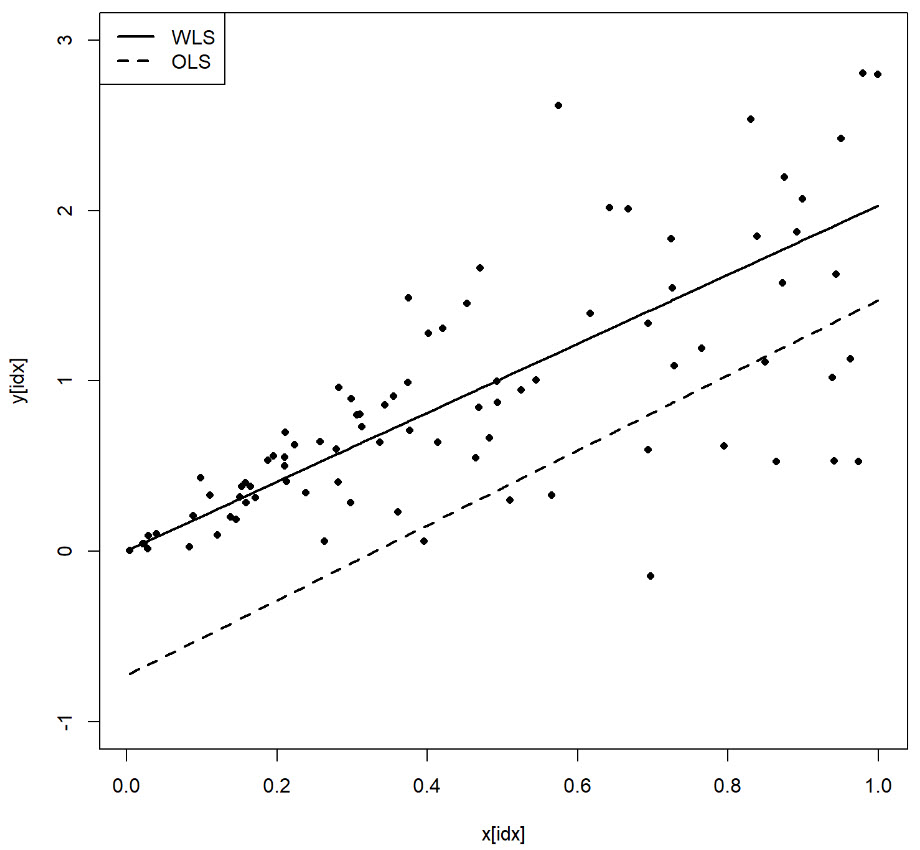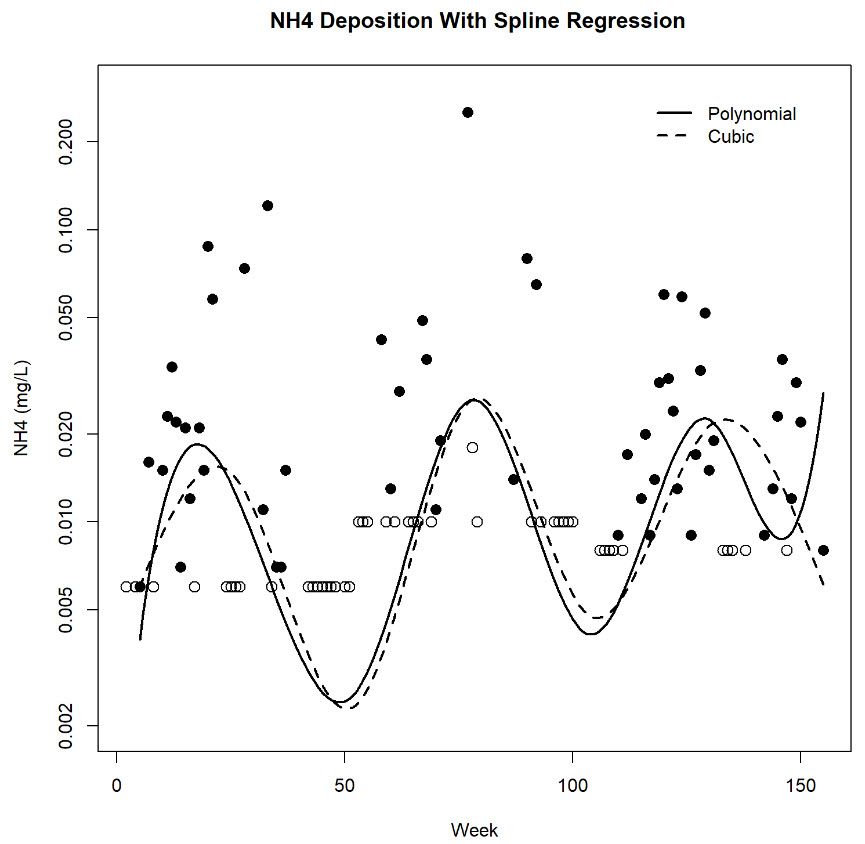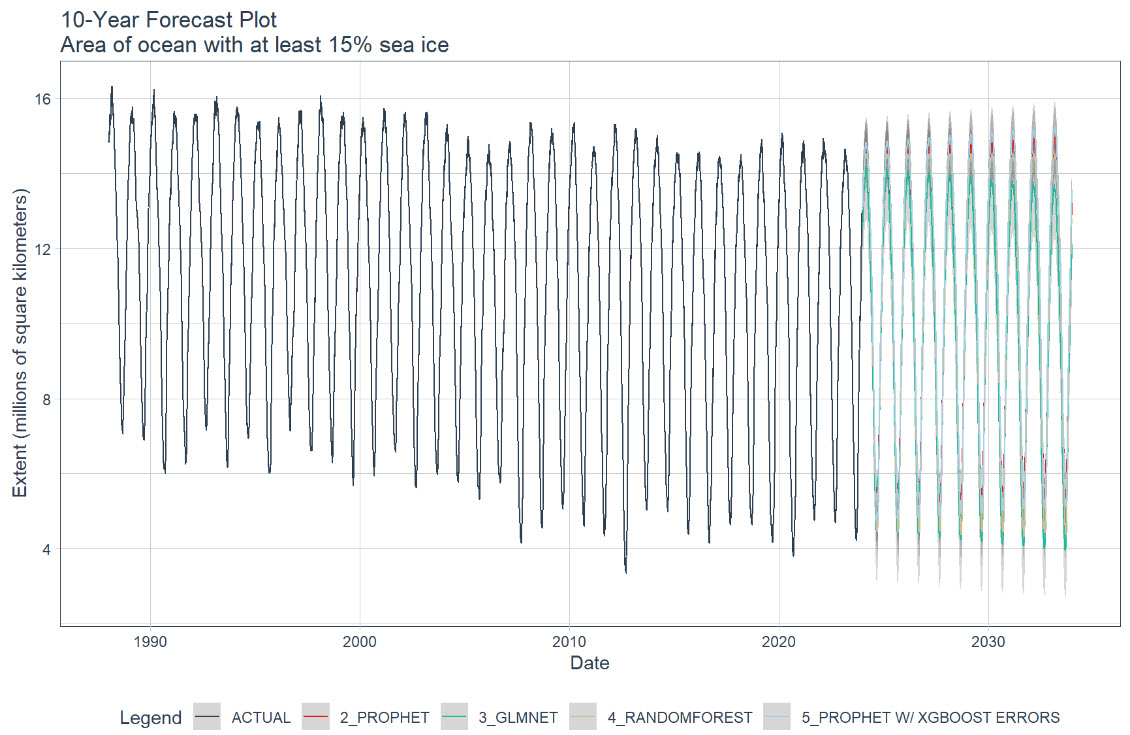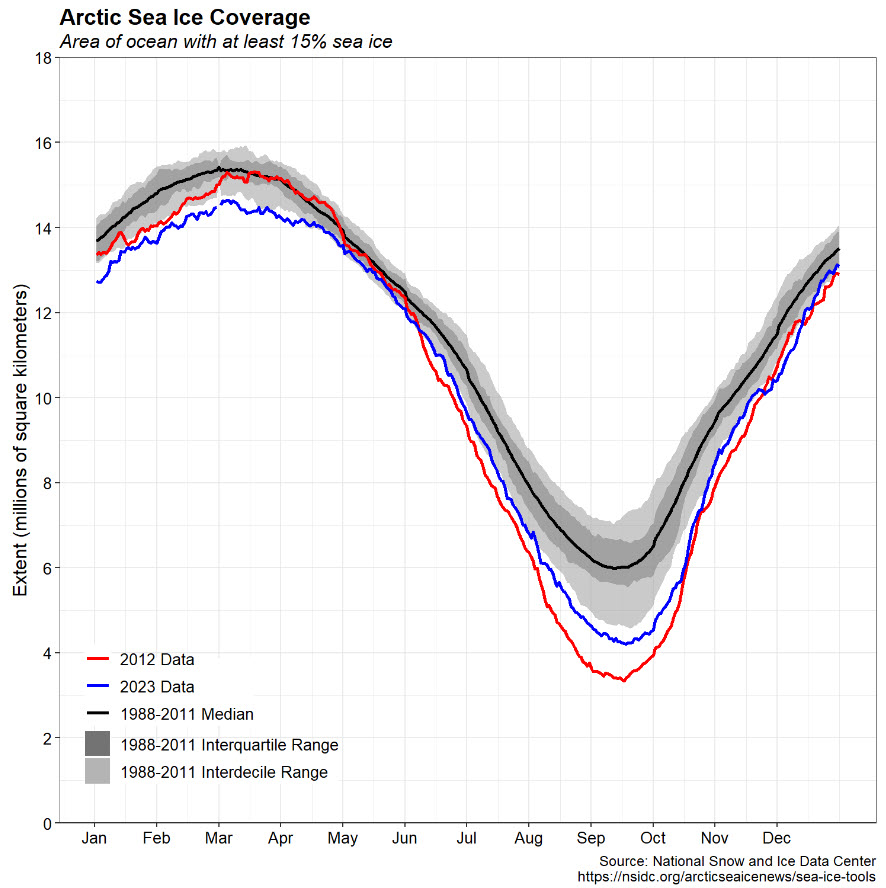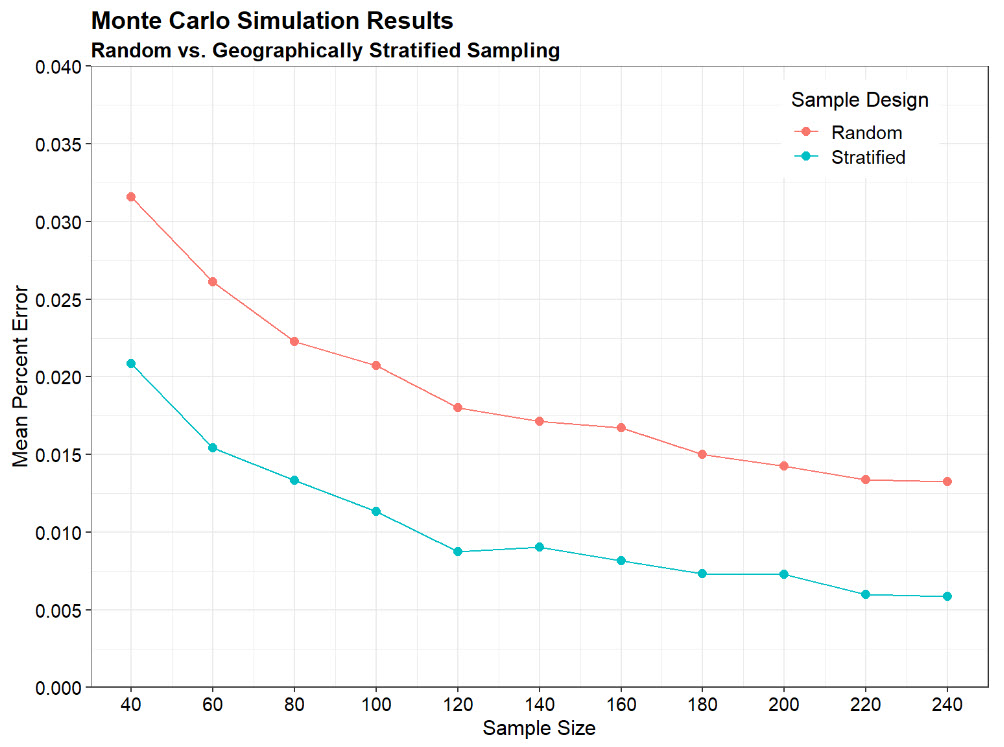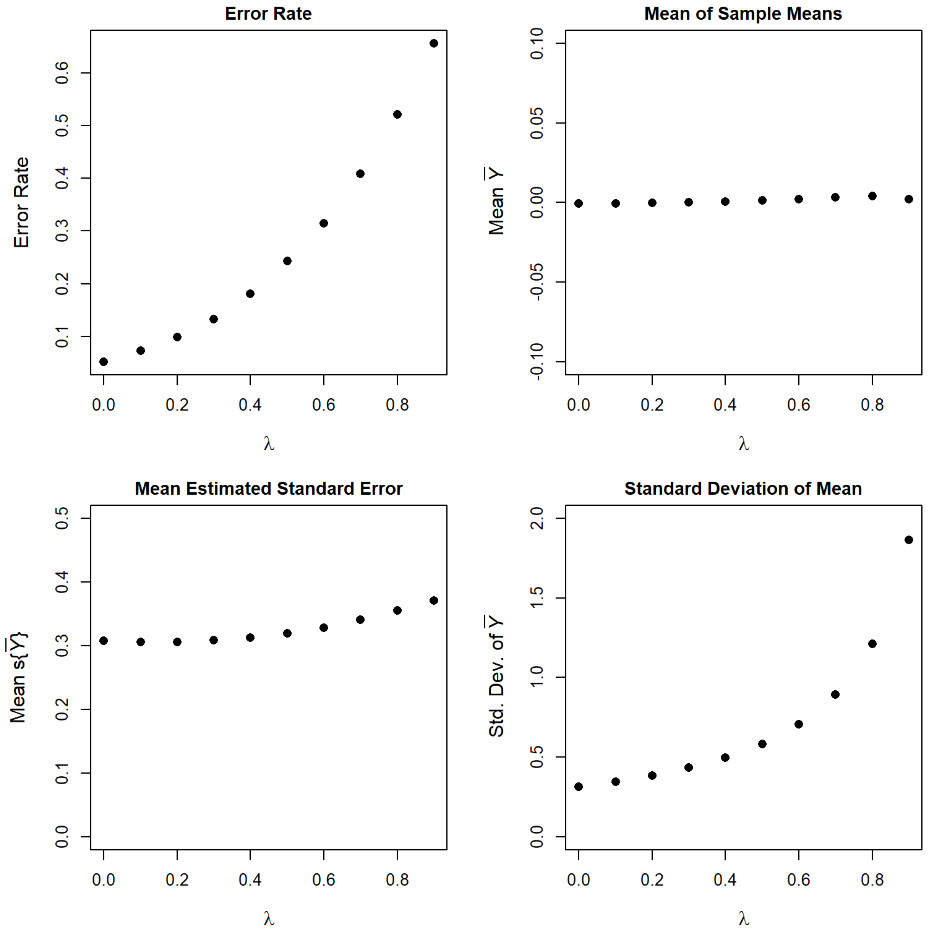
Statistical Properties of Autocorrelated Data
In classical statistical analysis, positive autocorrelation leads to an underestimation of the standard error because standard methods assume independence of data. This underestimation results in inflated test statistics, increasing the risk of incorrectly rejecting the null hypothesis. Autocorrelated data implies that each observation is related to nearby values, reducing the degrees of freedom and making the effective sample size smaller than the actual sample size. Monte Carlo simulation is used to explore the effect of autocorrelation on a hypothesis test to determine whether an observed data set is drawn from a population with mean zero.