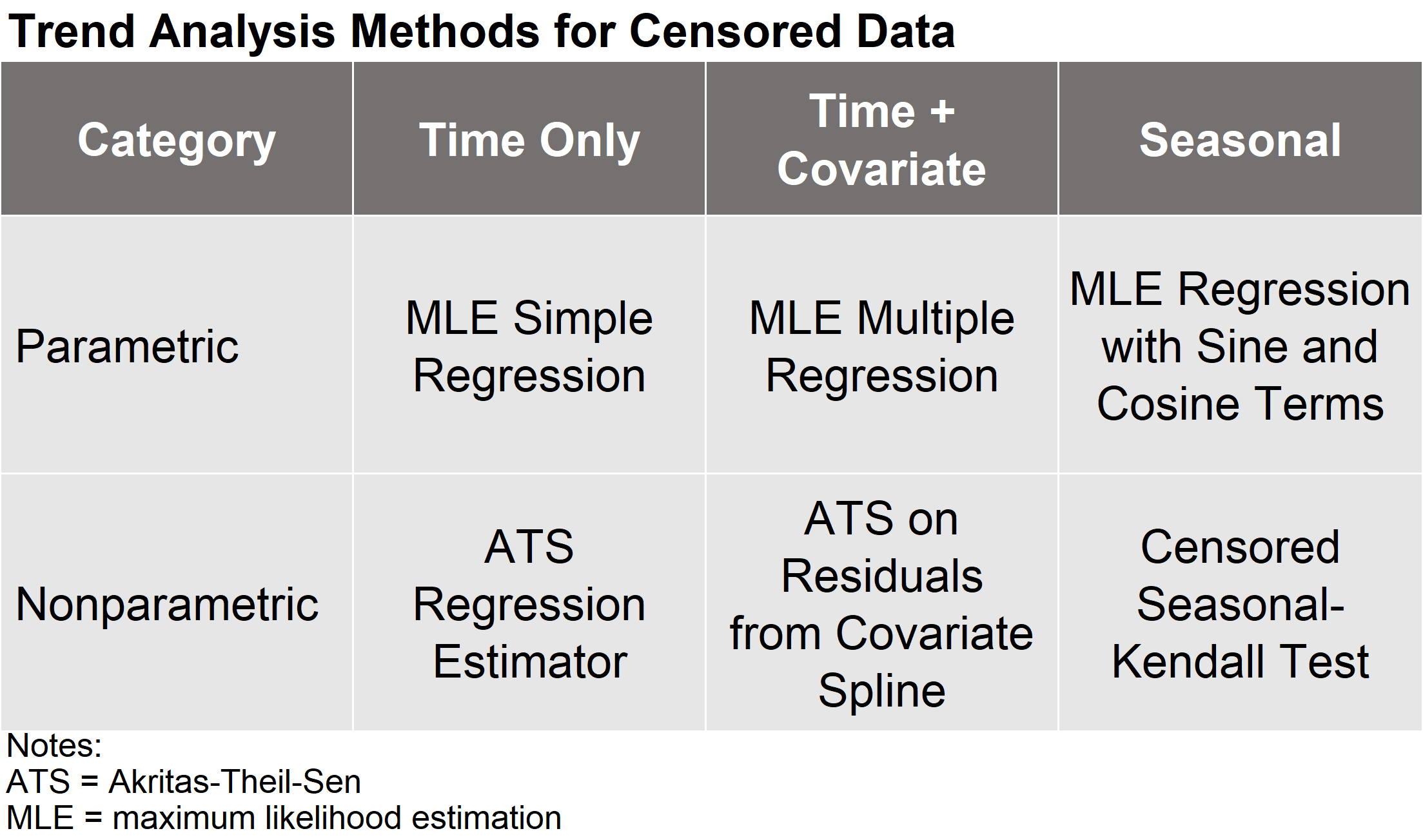
Sample Size Determination for Correlation Studies
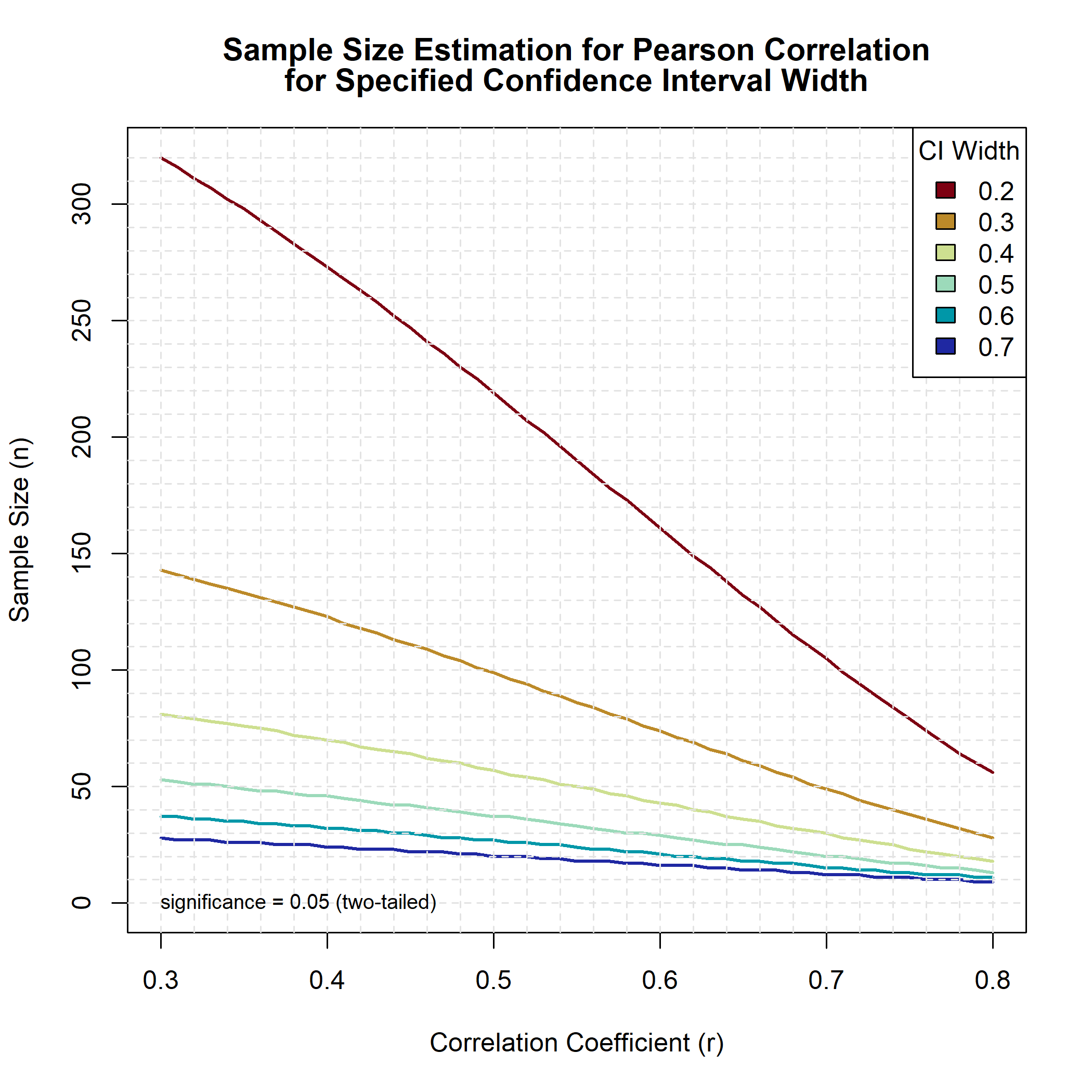
Determination of an appropriate sample size when performing a correlation sudy is usually based on achieving sufficient power that the test can reject the null hypothesis that the correlation is zero. Sample sizes found using this method can yield confidence intervals that are so wide that they provide very little useful information about the magnitude of the correlation. An alternative approach is to choose a sample size that achieves a sufficiently narrow confidence interval for measuring the smallest correlation of potential interest.